Codepages, character set, encoding... uh?

One of the most asked questions while training is about codepages or character sets. Ever met some strange characters in e-mails, documents or the internet? Like '???? ?? ???' or '¿¿¿¿' and others.
History bit/byte
Let us start from the beginning. To represent letters or characters they must be stored in the memory / hard disk wherever. As we all know, computers in general can only store 1 and 0. 1 and 0 refer to the state of one bit. So we got one bit, which can be either active(=set)=1 or inactive(=not set)=0. Now 1 byte are 8 bits nearly everywhere nowadays - why? Because it was determined to use this to encode (store) one character. From 2 states for 8 bits you end up with 2^8 = 256.
Storage / representation of characters
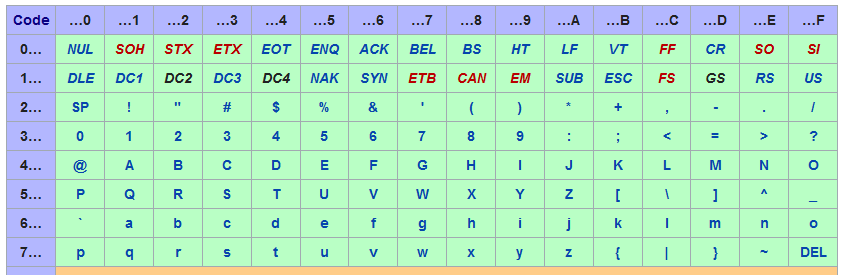
So we can store 256 different states in 1 byte. How can we express characters with this? The most and (if I remember correctly) first code chart and character encoding which was standardized for electronic communications is ASCII. There is a great picture at Wikipedia about it:

If you focus on the upper and left area you will notice 'Bits' with the description of b1 until b7. Based on the states of these bits the corresponding character is displayed. So:
- All bits set to 0 will result in 'NUL'
- All bits set to 1 will result in 'DEL'
- 0 0 0 0 1 1 0 will result in 0
- 0 0 0 1 1 1 0 will result in 8 Please note, that you have to pay attention on the order of bytes. Here I ordered them from b1 to b7, where as the table is ordering in reverse order (as the first bit in memory is the most right one).
I will further use hexadecimal for byte descriptions. Hexadecimal is a numbering system which has the base number of 16. As we only got 10 numbers (0 ... 9), the first characters of the alphabet are used in addition (A ... F). You can read more about it here.
To keep it short, 00 is NUL where es 30 is 0. If you have got notepad++ installed, you can view a great ASCII panel by using 'Edit' -> 'Character panel'. Furthermore, you can just double click to insert the character/hex/value (I use this for testing industrial devices with putty). On the german wikipedia there is a great ASCII-hex-table on the UTF-8 page:
'Special' or control characters
Beside the characters there was the need for some additional characters. These had been used for the control of the input by keyboard or controlling the printers. For example, FF does revere to 'Form Feed' - to eject the current page from the printer. Other famous are 'Carriage Return' and 'Line Feed' which execute 'go to position 1 of the line' and 'go to next line'. On each operation system they are interpreted a little bit different. E. g. Windows does require CRLF whereas Unix only does require LF for a line break. If you ever get in contact with older protocols, you will also get in contact with STX/ETX or SYN and so on which are mostly used in RS232 protocols or industrial devices. Do not ask me why they are still there (sometimes I have the feeling, that they just re-use damn old controllers), but for polling meter counters or scales within some milliseconds you do not want to use json or some other bloated protocol - you are just happy about least traffic as possible.
Other languages, other characters - problems arised
After taking a close look at the characters which are visible in the ASCII character encoding you will notice that there are only US characters. No other characters like french, german, norwegian, chinese, russian, arabaic and so on characters. As the memory was very limited in the beginning and each country and big tech company (especially Microsoft, IBM and Oracle) did not talk to each other many new character sets have been defined. Mostly for different regions, sometimes for countries and always depending on the operating system or source application.
As each character set is storing the characters differently, a conversion must apply. For converting between the character sets you must know from which to which you need to convert. But not all character sets support the same characters - so when you convert one text with a specific character set to another you may loose some characters depending on the character sets used.
Single byte and multi byte character sets
At some point the problems with the codepages and the conversions got that much that Unicode was born. Unicode is a 'multi-byte-character-set' (short MBCS) which does encode the characters in multiple bytes as one byte is not enough to encode the most written languages in the world (think of traditional chinese with round about 50.000 characters). There are some other MBCS like Shift-JIS, BIG5 or BG2312 beside Unicode but the most important are UTF-8, UTF-16 or UTF-32. Whereas UTF-8 is the most used character set in the internet.
I will further describe MBCS based on UTF-8 and in hexadecimal representation. Nearly every codepage does integrate ASCII with the original encoding. So ASCII characters are always safe. Following a short (incomplete) description:
- 00 -> 7F = One byte long, same as ASCII
- 80 -> BF = Second, third or fourth byte of a multi-byte-sequence
- C0 -> C1 = In short, invalid
- C2 -> DF = Start of a 2 byte long sequence
- E0 -> EF = Start of a 3 byte long sequence
- F0 -> F4 = Start of a 4 byte long sequence By using this declaration, it is possible to parse the encoding, detecting how many bytes together describe one character.
If you want to browse UTF-8 you can also take a look here.
.Net character set and file encoding
.Net does internally use UTF-16 to encode characters. If you want to read in a file in a different character set it is quite simple:
// load encoding 850
Encoding inputEncoding = Encoding.GetEncoding(850);
// read in file
string convertedText = File.ReadAllText(@"d:\test-850.txt", inputEncoding);
Nearly every class for accessing external resources is coming with a constructor which has got an overload to pass an encoding. The list of encodings is different from operating system to operating system, to see your encodings you can use GetEncodings. On the link you can also find a list of common encodings.
Converting bytes / strings
If you receive data by network, from a foreign system, you also mostly have to deal with encodings. For this, following code may come in handy:
// load encoding 850
Encoding inputEncoding = Encoding.GetEncoding(850);
// convert source byte array with character set 850 to string
string convertedString = inputEncoding.GetString(someReceivedData);
Other way round:
// load encoding 850
Encoding inputEncoding = Encoding.GetEncoding(850);
// convert string to target byte array in character set 850
byte[] convertedBytes = inputEncoding.GetBytes(convertedString);
If you are required/or interested in getting the number of bytes in a string you can also use the GetByteCount() method.
Thank you for reading!
Credits
Photo by Nathaniel Shuman on Unsplash




